
Twitter-Snowflakeń«Śµ│Ģõ║¦ńö¤ńÜäĶāīµÖ»ńøĖÕĮōń«ĆÕŹĢ’╝īõĖ║õ║åµ╗ĪĶČ│Twitterµ»Åń¦ÆõĖŖõĖćµØĪµČłµü»ńÜäĶ»Ęµ▒é’╝īµ»ÅµØĪµČłµü»ķāĮÕ┐ģķĪ╗ÕłåķģŹõĖƵØĪÕö»õĖĆńÜäid’╝īĶ┐Öõ║øidĶ┐śķ£ĆĶ”üõĖĆõ║øÕż¦Ķć┤ńÜäķĪ║Õ║Å’╝łµ¢╣õŠ┐Õ«óµłĘń½»µÄÆÕ║Å’╝ē’╝īÕ╣ČõĖöÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁõĖŹÕÉīµ£║ÕÖ©õ║¦ńö¤ńÜäidÕ┐ģķĪ╗õĖŹÕÉīŃĆé
Snowflakeń«Śµ│ĢµĀĖÕ┐ā
µŖŖµŚČķŚ┤µł│’╝īÕĘźõĮ£µ£║ÕÖ©id’╝īÕ║ÅÕłŚÕÅĘń╗äÕÉłÕ£©õĖĆĶĄĘŃĆé
┬Ā
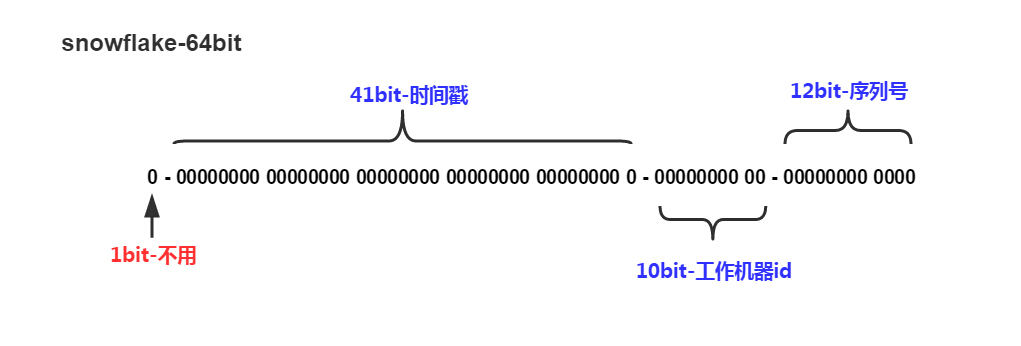
┬Ā
ķÖżõ║åµ£Ćķ½śõĮŹbitµĀćĶ«░õĖ║õĖŹÕÅ»ńö©õ╗źÕż¢’╝īÕģČõĮÖõĖēń╗äbitÕŹĀõĮŹÕØćÕÅ»µĄ«ÕŖ©’╝īń£ŗÕģĘõĮōńÜäõĖÜÕŖĪķ£Ćµ▒éĶĆīÕ«ÜŃĆéķ╗śĶ«żµāģÕåĄõĖŗ41bitńÜ䵌ČķŚ┤µł│ÕÅ»õ╗źµö»µīüĶ»źń«Śµ│ĢõĮ┐ńö©Õł░2082Õ╣┤’╝ī10bitńÜäÕĘźõĮ£µ£║ÕÖ©idÕÅ»õ╗źµö»µīü1023ÕÅ░µ£║ÕÖ©’╝īÕ║ÅÕłŚÕÅʵö»µīü1µ»½ń¦Æõ║¦ńö¤4095õĖ¬Ķć¬Õó×Õ║ÅÕłŚidŃĆéõĖŗµ¢ćõ╝ÜÕģĘõĮōÕłåµ×ÉŃĆé
┬Ā
Snowflake ŌĆō µŚČķŚ┤µł│
Ķ┐ÖķćīµŚČķŚ┤µł│ńÜäń╗åÕ║”µś»µ»½ń¦Æń║¦’╝īÕģĘõĮōõ╗ŻńĀüÕ”éõĖŗ’╝īÕ╗║Ķ««õĮ┐ńö©64õĮŹlinuxń│╗ń╗¤µ£║ÕÖ©’╝īÕøĀõĖ║µ£ēvdso’╝īgettimeofday()Õ£©ńö©µłĘµĆüÕ░▒ÕÅ»õ╗źÕ«īµłÉµōŹõĮ£’╝īÕćÅÕ░æõ║åĶ┐øÕģźÕåģµĀĖµĆüńÜ䵏¤ĶĆŚŃĆé
|
1
2
3
4
5
6
|
uint64_t generateStamp(){┬Ā┬Ā┬Ā┬Ātimeval tv;
┬Ā┬Ā┬Ā┬Āgettimeofday(&tv, 0);
┬Ā┬Ā┬Ā┬Āreturn (uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;
} |
ķ╗śĶ«żµāģÕåĄõĖŗµ£ē41õĖ¬bitÕÅ»õ╗źõŠøõĮ┐ńö©’╝īķéŻõ╣łõĖĆÕģ▒µ£ēT’╝ł1llu << 41’╝ēµ»½ń¦ÆõŠøõĮĀõĮ┐ńö©ÕłåķģŹ’╝īÕ╣┤õ╗Į = T / (3600 * 24 * 365 * 1000) = 69.7Õ╣┤ŃĆéÕ”éµ×£õĮĀÕŬń╗ÖµŚČķŚ┤µł│ÕłåķģŹ39õĖ¬bitõĮ┐ńö©’╝īķéŻõ╣łµĀ╣µŹ«ÕÉīµĀĘńÜäń«Śµ│Ģµ£ĆÕÉÄÕ╣┤õ╗Į = 17.4Õ╣┤ŃĆé
Snowflake ŌĆō ÕĘźõĮ£µ£║ÕÖ©id
õĖźµĀ╝µäÅõ╣ēõĖŖµØźĶ»┤Ķ┐ÖõĖ¬bitµ«ĄńÜäõĮ┐ńö©ÕÅ»õ╗źµś»Ķ┐øń©ŗń║¦’╝īµ£║ÕÖ©ń║¦ńÜäĶ»ØõĮĀÕÅ»õ╗źõĮ┐ńö©MACÕ£░ÕØĆµØźÕö»õĖƵĀćńż║ÕĘźõĮ£µ£║ÕÖ©’╝īÕĘźõĮ£Ķ┐øń©ŗń║¦ÕÅ»õ╗źõĮ┐ńö©IP+PathµØźÕī║ÕłåÕĘźõĮ£Ķ┐øń©ŗŃĆéÕ”éµ×£ÕĘźõĮ£µ£║ÕÖ©µ»öĶŠāÕ░æ’╝īÕÅ»õ╗źõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČµØźĶ«ŠńĮ«Ķ┐ÖõĖ¬idµś»õĖĆõĖ¬õĖŹķöÖńÜäķĆēµŗ®’╝īÕ”éµ×£µ£║ÕÖ©Ķ┐ćÕżÜķģŹńĮ«µ¢ćõ╗ČńÜäń╗┤µŖżµś»õĖĆõĖ¬ńüŠķÜŠµĆ¦ńÜäõ║ŗµāģŃĆé
Ķ┐ÖķćīńÜäĶ¦ŻÕå│µ¢╣µĪłµś»ķ£ĆĶ”üõĖĆõĖ¬ÕĘźõĮ£idÕłåķģŹńÜäĶ┐øń©ŗ’╝īÕÅ»õ╗źõĮ┐ńö©Ķć¬ÕĘ▒ń╝¢ÕåÖõĖĆõĖ¬ń«ĆÕŹĢĶ┐øń©ŗµØźĶ«░ÕĮĢÕłåķģŹid’╝īµł¢ĶĆģÕł®ńö©Mysql┬Āauto_incrementµ£║ÕłČõ╣¤ÕÅ»õ╗źĶŠŠÕł░µĢłµ×£ŃĆé

┬Ā
ÕĘźõĮ£Ķ┐øń©ŗõĖÄÕĘźõĮ£idÕłåķģŹÕÖ©ÕŬµś»Õ£©ÕĘźõĮ£Ķ┐øń©ŗÕÉ»ÕŖ©ńÜ䵌ČÕĆÖõ║żõ║ÆõĖƵ¼Ī’╝īńäČÕÉÄÕĘźõĮ£Ķ┐øń©ŗÕÅ»õ╗źĶć¬ĶĪīÕ░åÕłåķģŹńÜäidµĢ░µŹ«ĶÉĮµ¢ćõ╗Č’╝īõĖŗõĖƵ¼ĪÕÉ»ÕŖ©ńø┤µÄźĶ»╗ÕÅ¢µ¢ćõ╗ČķćīńÜäidõĮ┐ńö©ŃĆé
PS’╝ÜĶ┐ÖõĖ¬ÕĘźõĮ£µ£║ÕÖ©idńÜäbitµ«Ąõ╣¤ÕÅ»õ╗źĶ┐øõĖƵŁźµŗåÕłå’╝īµ»öÕ”éńö©ÕēŹ5õĖ¬bitµĀćĶ«░Ķ┐øń©ŗid’╝īÕÉÄ5õĖ¬bitµĀćĶ«░ń║┐ń©ŗidõ╣ŗń▒╗:D
Snowflake ŌĆō Õ║ÅÕłŚÕÅĘ
Õ║ÅÕłŚÕÅĘÕ░▒µś»õĖĆń│╗ÕłŚńÜäĶć¬Õó×id’╝łÕżÜń║┐ń©ŗÕ╗║Ķ««õĮ┐ńö©atomic’╝ē’╝īõĖ║õ║åÕżäńÉåÕ£©ÕÉīõĖƵ»½ń¦ÆÕåģķ£ĆĶ”üń╗ÖÕżÜµØĪµČłµü»ÕłåķģŹid’╝īĶŗźÕÉīõĖƵ»½ń¦ÆµŖŖÕ║ÅÕłŚÕÅĘńö©Õ«īõ║å’╝īÕłÖŌĆ£ńŁēÕŠģĶć│õĖŗõĖƵ»½ń¦ÆŌĆØŃĆé
|
1
2
3
4
5
6
7
8
|
uint64_t waitNextMs(uint64_t lastStamp){┬Ā┬Ā┬Ā┬Āuint64_t cur = 0;
┬Ā┬Ā┬Ā┬Ādo {
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ācur = generateStamp();
┬Ā┬Ā┬Ā┬Ā} while (cur <= lastStamp);
┬Ā┬Ā┬Ā┬Āreturn cur;
} |
┬Ā
µĆ╗õĮōµØźĶ»┤’╝īµś»õĖĆõĖ¬ÕŠłķ½śµĢłÕŠłµ¢╣õŠ┐ńÜäGUIDõ║¦ńö¤ń«Śµ│Ģ’╝īõĖĆõĖ¬int64_tÕŁŚµ«ĄÕ░▒ÕÅ»õ╗źĶā£õ╗╗’╝īõĖŹÕāÅńÄ░Õ£©õĖ╗µĄü128bitńÜäGUIDń«Śµ│Ģ’╝īÕŹ│õĮ┐µŚĀµ│Ģõ┐ØĶ»üõĖźµĀ╝ńÜäidÕ║ÅÕłŚµĆ¦’╝īõĮåµś»Õ»╣õ║Äńē╣Õ«ÜńÜäõĖÜÕŖĪ’╝īµ»öÕ”éńö©ÕüܵĖĖµłÅµ£ŹÕŖĪÕÖ©ń½»ńÜäGUIDõ║¦ńö¤õ╝ÜÕŠłµ¢╣õŠ┐ŃĆéÕÅ”Õż¢’╝īÕ£©ÕżÜń║┐ń©ŗńÜäńÄ»ÕóāõĖŗ’╝īÕ║ÅÕłŚÕÅĘõĮ┐ńö©atomicÕÅ»õ╗źÕ£©õ╗ŻńĀüÕ«×ńÄ░õĖŖµ£ēµĢłÕćÅÕ░æķöüńÜäÕ»åÕ║”ŃĆé
┬Ā
ń╗ōµ×äõĖ║’╝Ü
0---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---0000000000 00
Õ£©õĖŖķØóńÜäÕŁŚń¼”õĖ▓õĖŁ’╝īń¼¼õĖĆõĮŹõĖ║µ£¬õĮ┐ńö©’╝łÕ«×ķÖģõĖŖõ╣¤ÕÅ»õĮ£õĖ║longńÜäń¼”ÕÅĘõĮŹ’╝ē’╝īµÄźõĖŗµØźńÜä41õĮŹõĖ║µ»½ń¦Æń║¦µŚČķŚ┤’╝īńäČÕÉÄ5õĮŹdatacenterµĀćĶ»åõĮŹ’╝ī5õĮŹµ£║ÕÖ©ID’╝łÕ╣ČõĖŹń«ŚµĀćĶ»åń¼”’╝īÕ«×ķÖģµś»õĖ║ń║┐ń©ŗµĀćĶ»å’╝ē’╝īńäČÕÉÄ12õĮŹĶ»źµ»½ń¦ÆÕåģńÜäÕĮōÕēŹµ»½ń¦ÆÕåģńÜäĶ«ĪµĢ░’╝īÕŖĀĶĄĘµØźÕłÜÕźĮ64õĮŹ’╝īõĖ║õĖĆõĖ¬LongÕ×ŗŃĆé
Ķ┐ÖµĀĘńÜäÕźĮÕżäµś»’╝īµĢ┤õĮōõĖŖµīēńģ¦µŚČķŚ┤Ķć¬Õó×µÄÆÕ║Å’╝īÕ╣ČõĖöµĢ┤õĖ¬ÕłåÕĖāÕ╝Åń│╗ń╗¤ÕåģõĖŹõ╝Üõ║¦ńö¤IDńó░µÆ×’╝łńö▒datacenterÕÆīµ£║ÕÖ©IDõĮ£Õī║Õłå’╝ē’╝īÕ╣ČõĖöµĢłńÄćĶŠāķ½ś’╝īń╗ŵĄŗĶ»Ģ’╝īsnowflakeµ»Åń¦ÆĶāĮÕż¤õ║¦ńö¤26õĖćIDÕĘ”ÕÅ│’╝īÕ«īÕģ©µ╗ĪĶČ│ķ£ĆĶ”üŃĆé
┬Ā
public class IdWorker {
private final long workerId;
private final static long twepoch = 1361753741828L;
private long sequence = 0L;
private final static long workerIdBits = 4L;
private final static long maxWorkerId = -1L ^ -1L << workerIdBits;
private final static long sequenceBits = 10L;
private final static long workerIdShift = sequenceBits;
private final static long timestampLeftShift = sequenceBits + workerIdBits;
private final static long sequenceMask = -1L ^ -1L << sequenceBits;
private long lastTimestamp = -1L;
public IdWorker(final long workerId) {
super();
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format(
"worker Id can't be greater than %d or less than 0", maxWorkerId));
}
this.workerId = workerId;
}
public synchronized long nextId() {
long timestamp = this.timeGen();
if (this.lastTimestamp == timestamp) {
this.sequence = (this.sequence + 1) & sequenceMask;
if (this.sequence == 0) {
System.out.println("###########" + sequenceMask);
timestamp = this.tilNextMillis(this.lastTimestamp);
}
} else {
this.sequence = 0;
}
if (timestamp < this.lastTimestamp) {
try {
throw new Exception(String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds",
this.lastTimestamp - timestamp));
} catch (Exception e) {
e.printStackTrace();
}
}
this.lastTimestamp = timestamp;
long nextId = ((timestamp - twepoch << timestampLeftShift))
| (this.workerId << workerIdShift) | (this.sequence);
// System.out.println("timestamp:" + timestamp + ",timestampLeftShift:"
// + timestampLeftShift + ",nextId:" + nextId + ",workerId:"
// + workerId + ",sequence:" + sequence);
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) throws InterruptedException {
IdWorker worker2 = new IdWorker(2);
System.out.println(worker2.nextId());
Thread.sleep(1000L);
System.out.println(worker2.nextId());
}
}
┬Ā
┬Ā
Reference:



ńøĖÕģ│µÄ©ĶŹÉ
TwitterńÜäÕłåÕĖāÕ╝ÅĶć¬Õó×IDń«Śµ│Ģsnowflake (Javańēł)
TwitterńÜäÕłåÕĖāÕ╝ÅĶć¬Õó×IDķø¬ĶŖ▒ń«Śµ│Ģsnowflake (Javańēł)
õĖ╗Ķ”üõ╗ŗń╗Źõ║åJavaÕ«×ńÄ░TwitterńÜäÕłåÕĖāÕ╝ÅĶć¬Õó×IDń«Śµ│Ģsnowflake’╝īµ¢ćõĖŁķĆÜĶ┐ćńż║õŠŗõ╗ŻńĀüõ╗ŗń╗ŹńÜäķØ×ÕĖĖĶ»”ń╗å’╝īÕ»╣Õż¦Õ«ČńÜäÕŁ”õ╣Āµł¢ĶĆģÕĘźõĮ£Õģʵ£ēõĖĆÕ«ÜńÜäÕÅéĶĆāÕŁ”õ╣Āõ╗ĘÕĆ╝’╝īķ£ĆĶ”üńÜäµ£ŗÕÅŗõ╗¼õĖŗķØóķÜÅńØĆÕ░Åń╝¢µØźõĖĆĶĄĘÕŁ”õ╣ĀÕŁ”õ╣ĀÕɦ
Twitter Snowflakeń«Śµ│Ģ’╝īphpńēłõ╗ŻńĀü’╝ø Ķ»ĘĶ¦üÕŹÜÕ«ó’╝Ü http://blog.csdn.net/envon123/article/details/52953872
ĶĆītwitterńÜäsnowflakeĶ¦ŻÕå│õ║åĶ┐Öń¦Źķ£Ćµ▒é’╝īµ£ĆÕłØµś»TwitterµŖŖÕŁśÕé©ń│╗ń╗¤õ╗ÄMySQLĶ┐üń¦╗Õł░Cassandra’╝īÕøĀõĖ║Cassandraµ▓Īµ£ēķĪ║Õ║ÅńÜäIDńö¤µłÉµ£║ÕłČ’╝īµēĆõ╗źÕ╝ĆÕÅæõ║åĶ┐ÖµĀĘõĖĆÕźŚÕö»õĖĆńÜäIDńö¤µłÉµ£ŹÕŖĪŃĆéń╗ōµ×äķø¬ĶŖ▒ńÜäń╗ōµ×äÕ”éõĖŗ’╝łµ»Åķā©Õłåńö©-ÕłåÕ╝Ć’╝ē’╝Ü 0 - ...
We have retired the initial release of Snowflake and working on open sourcing the next version based on Twitter-server, in a form that can run anywhere without requiring Twitter's own infrastructure ...
ķø¬ĶŖ▒ń«Śµ│Ģ’╝īÕłåÕĖāÕ╝Åidńö¤µłÉń«Śµ│ĢńÜäµ£ēÕŠłÕżÜń¦Ź’╝īTwitterńÜäSnowFlakeÕ░▒µś»ÕģČõĖŁń╗ÅÕģĖńÜäõĖĆń¦ŹŃĆé
ķø¬ĶŖ▒ń«Śµ│ĢÕłåÕĖāÕ╝ÅIDńö¤µłÉÕÖ© Ķ┐ÖõĖ¬ķĪ╣ńø«ńÜäńø«ńÜ䵜»µÅÉõŠøõĖĆõĖ¬ĶĮ╗ķćÅń║¦’╝īķ½śÕ╣ČÕÅæ’╝īķ½śÕÅ»ńö©ńÜäńö¤µłÉÕö»õĖĆIDńÜäµ£ŹÕŖĪ’╝īńö¤µłÉńÜäIDµś»õĖĆõĖ¬64õĮŹńÜäķĢ┐µĢ┤Õ×ŗ’╝īÕĮ╝µŁżÕö»õĖĆ’╝īõ┐صīüķĆÆÕó×’╝īńøĖÕ»╣µ£ēÕ║ÅŃĆéµØźńö¤µłÉID’╝īńö©õ║ÄÕÅ¢õ╗ŻUUIDń▒╗Õ×ŗµŚĀÕ║Å’╝ī128õĮŹńÜäÕŁŚń¼”õĖ▓ÕĮóÕ╝ÅńÜäID...
nodejs-snowflakeµś»õĖĆń¦ŹÕ┐½ķƤÕÅ»ķØĀńÜäµ¢╣µ│Ģ’╝īÕÅ»õ╗źõĖ║ÕłåÕĖāÕ╝Åń│╗ń╗¤ńö¤µłÉµŚČķŚ┤ÕÅ»µÄÆÕ║ÅńÜä64õĮŹIDŃĆé õĖ╗Ķ”üńÜäIDńö¤µłÉÕŖ¤ĶāĮµś»õĮ┐ńö©N-APIńö©C ++ń╝¢ÕåÖńÜä’╝īĶ┐ÖõĮ┐ÕŠŚIDńö¤µłÉńÜäĶ┐ćń©ŗķØ×ÕĖĖÕ┐½ŃĆé õĮ┐ńö©C ++Ķ┐øĶĪīidńö¤µłÉĶ┐śÕÅ»õ╗źńĪ«õ┐Øńö¤µłÉńÜäµĢ░ÕŁŚÕż¦Õ░ÅõĖ║64õĮŹŃĆé ...
snowflakeń«Śµ│Ģµś»õĖ¬ÕĢź’╝¤ķ”¢ÕģłµłæµØźµÅÉÕć║õĖ¬ķŚ«ķóś’╝īµĆÄõ╣łÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńö¤µłÉÕö»õĖƵƦidÕ╣Čõ┐صīüĶ»źidÕż¦Ķć┤Ķć¬Õó×’╝¤Õ£©twitterõĖŁĶ┐Öµś»µ£ĆķćŹĶ”üńÜäõĖÜÕŖĪÕ£║µÖ»’╝īõ║ĵś»twitterµÄ©Õć║õ║åõĖĆń¦Źsnowflakeń«Śµ│ĢŃĆé
ķø¬ĶŖ▒ń«Śµ│ĢÕłåÕĖāÕ╝ÅIDńö¤µłÉÕÖ© Ķ»źķĪ╣ńø«ńÜäńø«ńÜ䵜»µÅÉõŠøõĖĆõĖ¬ĶĮ╗ķćÅń║¦ŃĆüķ½śÕ╣ČÕÅæŃĆüķ½śÕÅ»ńö©ńÜäńö¤µłÉÕö»õĖĆIDńÜäµ£ŹÕŖĪ’╝īńö¤µłÉńÜäIDµś»õĖĆõĖ¬64õĮŹńÜä ķĢ┐µĢ┤Õ×ŗ’╝īÕģ©Õ▒ĆÕö»õĖĆ’╝īõ┐صīüķĆÆÕó×’╝īńøĖÕ»╣µ£ēÕ║ÅŃĆéÕ¤║õ║ÄtwitterńÜäķø¬ĶŖ▒ń«Śµ│ĢµØźńö¤µłÉID,ńö©õ║ÄÕÅ¢õ╗ŻUUIDķéŻń¦ŹµŚĀÕ║ÅŃĆü...
snowflakeń«Śµ│Ģµś»TwitterÕ╝Ƶ║ÉńÜäÕłåÕĖāÕ╝ÅIDńö¤µłÉń«Śµ│Ģ’╝īń╗ōµ×£µś»õĖĆõĖ¬longń▒╗Õ×ŗńÜäID ŃĆéÕģȵĀĖÕ┐āµĆصā│’╝ÜõĮ┐ńö©41bitõĮ£õĖ║µ»½ń¦ÆµĢ░’╝ī10bitõĮ£õĖ║µ£║ÕÖ©ńÜäID’╝ł5bitµĢ░µŹ«õĖŁÕ┐ā’╝ī5bitńÜäµ£║ÕÖ©ID’╝ē’╝ī12bitõĮ£õĖ║µ»½ń¦ÆÕåģńÜ䵥üµ░┤ÕÅĘ’╝łµäÅÕæ│ńØƵ»ÅõĖ¬ĶŖéńé╣Õ£©µ»ÅõĖ¬...
Twitter ńÜä snowflake Õ£©ÕłåÕĖāÕ╝Åńö¤µłÉÕö»õĖĆ UUID Õ║öńö©Ķ┐śµś»Ķø«Õ╣┐µ│øńÜä’╝īÕ¤║õ║Ä snowflake ńÜäõĖĆõ║øÕÅśń¦ŹńÜäń«Śµ│ĢńĮæõĖŖõ╣¤µ£ēõĖŹÕ░æŃĆéõĮ┐ńö© snowflake ńö¤µłÉ UUID ÕŠłÕżÜķāĮµś»Õ£©ÕłåÕĖāÕ╝ÅÕ£║µÖ»õĖŗõĮ┐ńö©’╝īµłæń£ŗõ║åõĖŗńĮæõĖŖµ£ēÕģČõĖŁµ£ēÕćĀń»ć PHP Õ«×ńÄ░ńÜäķāĮµ▓Īµ£ē...
µÅÉÕł░idńö¤µłÉÕÖ©’╝ītwitterńÜäsnowflakeń«Śµ│Ģ õĖŹÕŠŚõĖŹĶó½µÅÉĶĄĘ’╝īõĮåµś»snowflakeńÜäń«Śµ│ĢÕøĀõĖ║õĮ┐ńö©õ║åõ║īĶ┐øÕłČńÜäń¦╗õĮŹÕüܵ│Ģ’╝īÕ»╝Ķć┤ÕģČńö¤µłÉńÜäń«Śµ│ĢĶ┐ć Õ║”ńÜäÕ»╣õ║ĵ£║ÕÖ©ÕÅŗÕźĮ’╝īÕ»╣õ║Äõ║║ń▒╗Õ╣ČõĖŹµś»ķéŻõ╣łńÜäÕÅŗÕźĮ’╝īõ╣¤Õ░▒µś»Ķ»┤snowflakeńö¤µłÉńÜäidÕ»╣õ║Äõ║║ń▒╗µØź Ķ»┤...
SnowFlake ń«Śµ│Ģ’╝īµś» Twitter Õ╝Ƶ║ÉńÜäÕłåÕĖāÕ╝Å id ńö¤µłÉń«Śµ│ĢŃĆéÕģȵĀĖÕ┐āµĆصā│Õ░▒µś»’╝ÜõĮ┐ńö©õĖĆõĖ¬ 64 bit ńÜä long Õ×ŗńÜäµĢ░ÕŁŚõĮ£õĖ║Õģ©Õ▒ĆÕö»õĖĆ idŃĆéÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńÜäÕ║öńö©ÕŹüÕłåÕ╣┐µ│ø’╝īõĖöID Õ╝ĢÕģźõ║åµŚČķŚ┤µł│’╝īÕ¤║µ£¼õĖŖõ┐صīüĶć¬Õó×ńÜä’╝īÕÉÄķØóńÜäõ╗ŻńĀüõĖŁµ£ē...
õĖĆõĖ¬Õ¤║õ║ÄSnowflakeń«Śµ│ĢPHP IDńö¤µłÉÕÖ©’╝łTwitterÕĘ▓Õ«ŻÕĖā’╝ēŃĆéµÅÅĶ┐░ķø¬ĶŖ▒ń«Śµ│ĢPHPÕ«×ńÄ░ŃĆé Snowflakeµś»õĖĆķĪ╣ńĮæń╗£µ£ŹÕŖĪ’╝īÕÅ»ķĆÜĶ┐ćõĖĆõ║øń«ĆÕŹĢńÜäõ┐ØĶ»üÕż¦Ķ¦äµ©Īńö¤µłÉÕö»õĖĆńÜäIDÕÅĘŃĆé ń¼¼õĖĆõĮŹµś»µ£¬õĮ┐ńö©ńÜäń¼”ÕÅĘõĮŹŃĆé ń¼¼õ║īķā©ÕłåÕīģµŗ¼õĖĆõĖ¬41õĮŹńÜ䵌ČķŚ┤µł│...
twitterķø¬ĶŖ▒ń«Śµ│ĢńÜäjavaÕ«×ńÄ░’╝īÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īµ£ēõĖĆõ║øķ£ĆĶ”üõĮ┐ńö©Õģ©Õ▒ĆÕö»õĖĆIDńÜäÕ£║µÖ»’╝īĶ┐Öń¦ŹµŚČÕĆÖõĖ║õ║åķś▓µŁóIDÕå▓ń¬üÕÅ»õ╗źõĮ┐ńö©36õĮŹńÜäUUID’╝īõĮåµś»UUIDµ£ēõĖĆõ║øń╝║ńé╣’╝īķ”¢Õģłõ╗¢ńøĖÕ»╣µ»öĶŠāķĢ┐’╝īÕÅ”Õż¢UUIDõĖĆĶł¼µś»µŚĀÕ║ÅńÜäŃĆé µ£ēõ║øµŚČÕĆÖµłæõ╗¼ÕĖīµ£øĶāĮõĮ┐ńö©...
õĖĆõĖ¬Õ«×ńÄ░ Twitter SnowFlake ń«Śµ│Ģ ńÜä Go ÕłåÕĖāÕ╝Å UID ńö¤µłÉÕÖ©
ķ½śµĢłGUIDõ║¦ńö¤ń«Śµ│Ģ(sequence),Õ¤║õ║ÄSnowflakeÕ«×ńÄ░64õĮŹĶć¬Õó×IDń«Śµ│ĢŃĆéµ¢░Õó×ńē╣µĆ¦’╝ܵö»µīüĶć¬Õ«Üõ╣ēÕģüĶ«ĖµŚČķŚ┤Õø×µŗ©ńÜäĶīāÕø┤Ķ¦ŻÕå│ĶĘ©µ»½ń¦ÆĶĄĘÕ¦ŗÕĆ╝µ»Åµ¼ĪõĖ║0Õ╝ĆÕ¦ŗńÜäµāģÕåĄ’╝łķü┐ÕģŹµ£½Õ░ŠÕ┐ģÕ«ÜõĖ║ÕüȵĢ░’╝īĶĆīõĖŹõŠ┐õ║ÄÕÅ¢õĮÖõĮ┐ńö©ķŚ«ķóś’╝ēĶ¦ŻÕå│ķ½śÕ╣ČÕÅæÕ£║µÖ»õĖŁĶÄĘÕÅ¢...
TwitterńÜäķø¬ĶŖ▒ń«Śµ│ĢSnowFlake’╝īõĮ┐ńö©Javaõ╗ŻńĀüÕ«×ńÄ░ŃĆé ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īµ£ēõĖĆõ║øķ£ĆĶ”üõĮ┐ńö©Õģ©Õ▒ĆÕö»õĖĆIDńÜäÕ£║µÖ»’╝īĶ┐Öń¦ŹµŚČÕĆÖõĖ║õ║åķś▓µŁóIDÕå▓ń¬üÕÅ»õ╗źõĮ┐ńö©36õĮŹńÜäUUID’╝īõĮåµś»UUIDµ£ēõĖĆõ║øń╝║ńé╣’╝īķ”¢Õģłõ╗¢ńøĖÕ»╣µ»öĶŠāķĢ┐’╝īÕÅ”Õż¢UUIDõĖĆĶł¼µś»µŚĀÕ║ÅńÜäŃĆéµ£ēõ║ø...